[請點按左列各項理由顯示內容]
Arbutus提供多種有用的資料表檢視功能:
- 利用拖放(Drag and Drop)方式,直接把欄位名稱拖放到篩選區塊中,可提供使用者簡易地針對該欄位建立篩選條件。
- “用紅色顯示負數”功能,提供使用者容易檢視負數值。
- 快速篩選中的”取代”功能,提供使用者直接指定新的篩選條件,來取代現有的篩選條件。
- “智慧搜尋(Smart Search)”提供”Google-like”的方式搜尋您的資料。
- 最佳化的篩選處理引擎,當資料量大時,能智慧地處理檢視視窗中的資料筆數,確保使用者檢視資料時不因資料量大而影響效能。
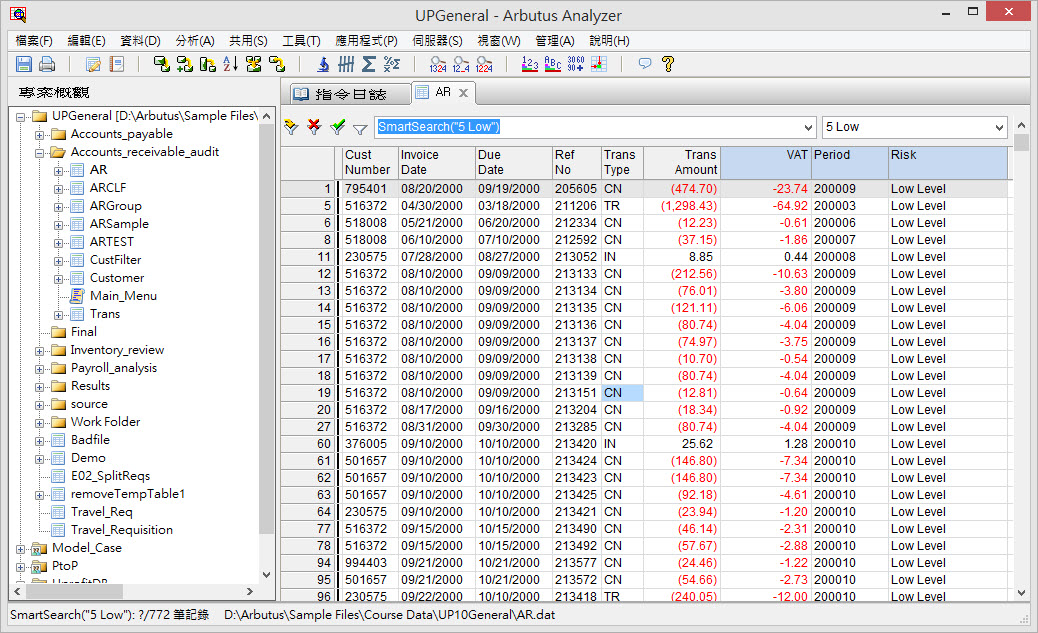
Format()指令能辨別欄位的資料格式,例如,使用Format(“12345-AbC) 指令,Arbutus能辨識出資料格式為”99999-XxX“。此功能特別可用來分析資料品質,並確保異常都已被清楚地註記。
使用Format()指令所產出的演算欄位,亦可執行分類(Classify)指令,瞭解您的資料中的資料格式類型。
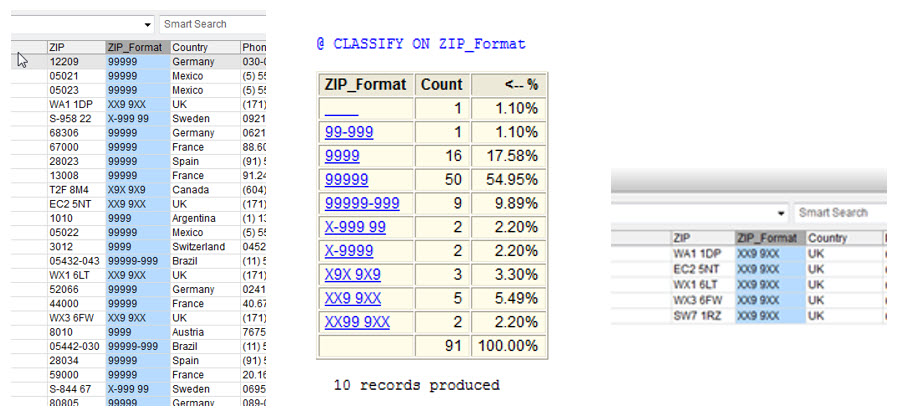
Arbutus的程序(Procedure)中,能使用RUN指令來執行其他應用程式(例如:Notepad)或是執行內嵌的DOS指令來達成需求。使用者甚至能使用RUN指令來執行DOS批次檔,來完成複雜的工作。
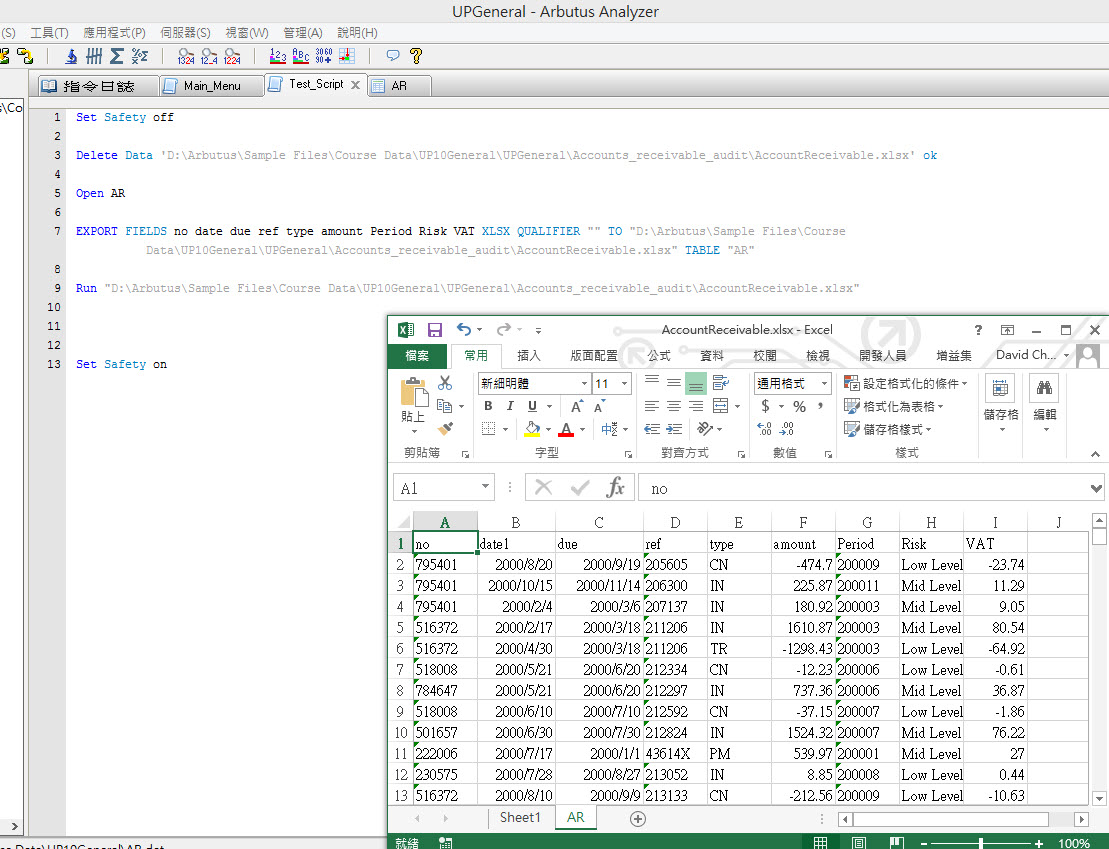
當使用者使用聯結(Join)指令時,能直接點擊對話框視窗中的「文氏圖」(Venn Diagram),來切換不同的聯結模式。提供使用者比下拉式選單更直接且直覺的選擇介面
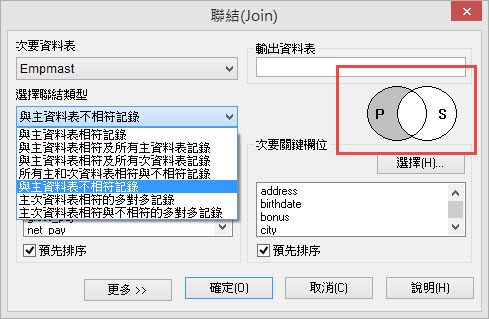
當使用者進行ODBC查詢時,能在查詢時預先聯結(Join)多個資料表。使用者對於資料表的聯結擁有完全控制能力。可選擇特定的欄位,或進行WHERE條件式篩選資料。
此外,使用者可選擇是否平面化數據資料(抓取資料表當時的狀態)或是直接讀取資料(可隨著資料變動重新整理)。
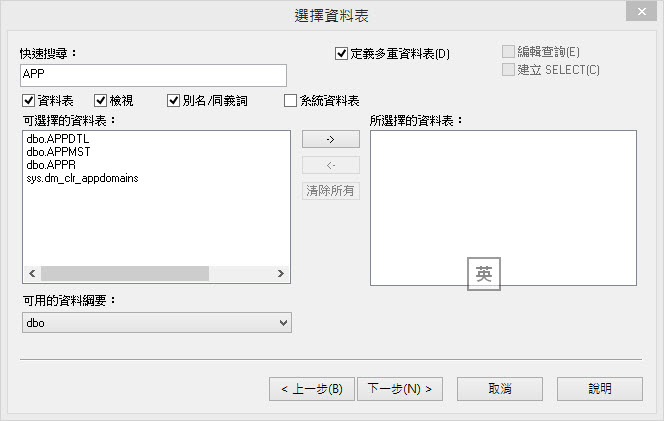
最後,”快速搜尋”能提供使用者從長資料表名稱清單中,快速的識別所需資料。例如,搜尋”Invoice”,則包含”Invoice”名稱的所有資料表如”Invoice Details”, ”Invoice Headers”及”Summary Invoice”都會被搜尋出來。此功能亦會排除所有與搜尋名稱無關的資料表。方便使用者尋找所需的資料表。

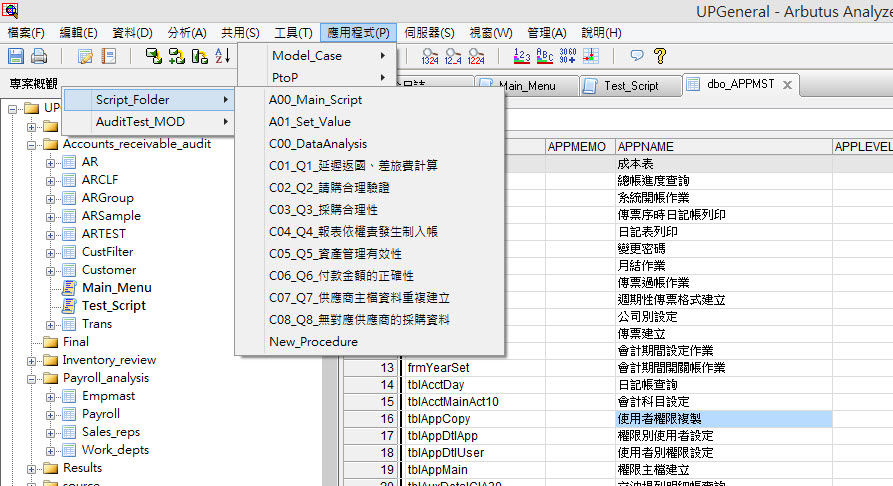
共用資料夾是Arbutus獨特的強大功能,可提供小組、部門或組織資料存取資料能確保一致性。應用程式選單的支援,更增強了共用資料夾的可用性。任何已被共用的程序(Procedure),能自動地顯示在Arbutus的應用程式選單中,以便於使用者使用。Arbutus以資料夾分層顯示的方式,提供直覺化的管理與使用介面。
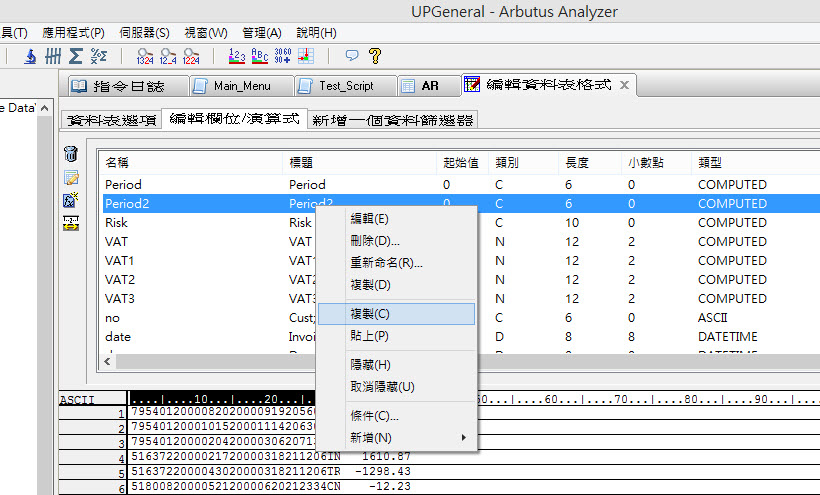
使用者能隨時地製作Arbutus的任何欄位的副本,此功能對於需要建立相似格式的欄位時相當有用。
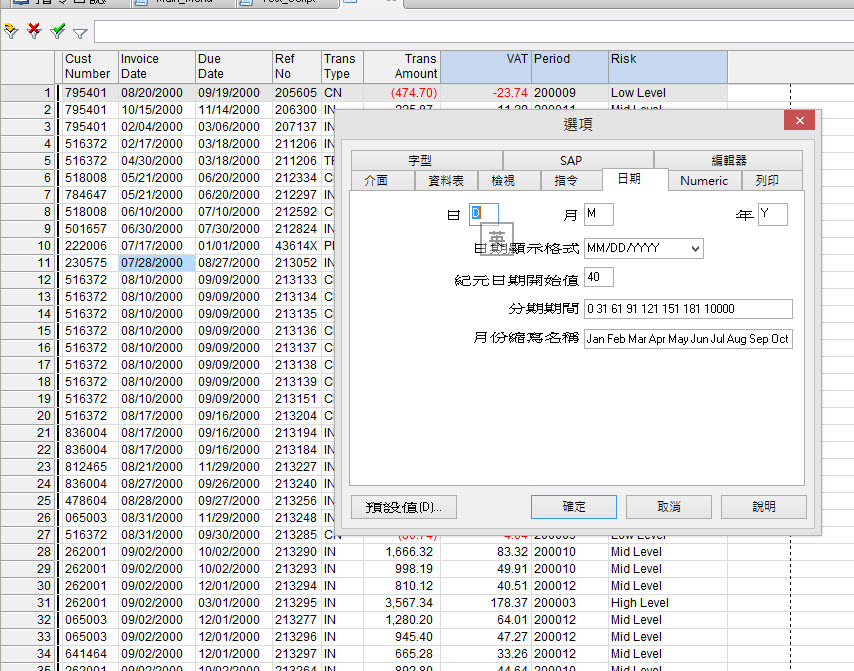
在日期和時間功能搭配結合的支持下,Arbutus能夠呈現日期和時間常數的所有方式。除了指定的日期和/或時間,Arbutus允許您指定經過時間。例如,這可以用於辨別發生在每隔15分鐘內的交易,以確定當時間時鐘輸入和輸出時間超過8小時的間隔記錄。
Date()指令通常用來轉換日期格式為字串格式,除了以預設格式建立日期外,此功能支持使用者自訂日期顯示格式。例如使用Date(start_time, “YYYY-MMM-DD”)指令,產生的日期顯示結果即為”2012-Mar-17”,Arbutus支援任何日期顯示格式。
使用者於Arbutus刪除的所有物件,像是資料表、程序等物件,會自動將所關聯的實體檔案放置於Windows系統的資源回收筒中。此功能可防止使用者誤刪到不該刪除的物件,可簡單快速還原誤刪的資料。

Performance Comparison: Arbutus vs. The Competition
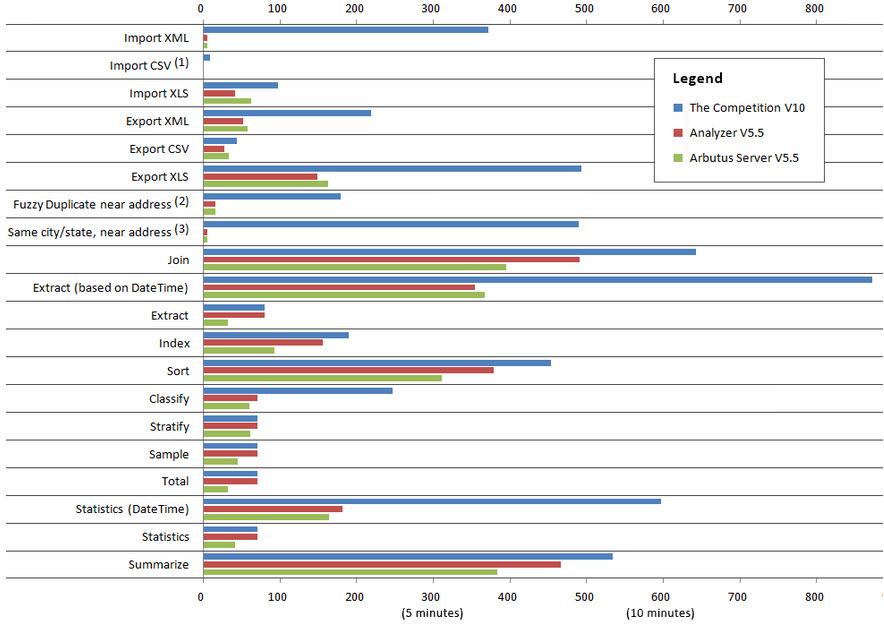
XML: 74 times faster
Delimited/CSV: Instantaneous
XLS/XLSX: 2 times fasterExporting
XML: 4 times faster
XLS/XLSX: 3 times fasterFuzzy matching: 11 to 500 times fasterUse of time fields: 2 to 3 times faster
1) In Arbutus, Import CSV takes zero time, regardless of file size, as delimited data is read directly.
2) Our Duplicates command is compared to their FUZZYDUP.
3) As their FUZZYDUP command does not support 'same' fields, we have concatenated the three keys.About the Tests:
- Test computer specs: Dell I7-920, 2.67GHz, Windows 64 bit, 9GB RAM, 1TB disk
- Most reads use a 125,000,000 record, 80 bytes long transaction file (10GB data size)
- Fuzzy duplicates tests use a 50,000 record address file
- Exports are 5,000,000 records, except Excel, which is 650,000
- Imports are all 650,000 records
- We chose 125 million records because most people interested in performance have big data. For comparison, Arbutus also ran the "big data" tests (Join through Summarize) on a 5 million record file as well. Analyzer took 50 seconds in total, while the competitor's version 10 took 89 seconds (the graph lines were too small to show individually).



