[請點按左列各項理由顯示內容]
任何共用程序(shared procedures)會自動加入應用程式選單(Applications menu),你的共用資料夾結構被維護在選單裡,讓我們很容易支持標準作業,而不需去維護太複雜的選單檔案(.MNU files)。
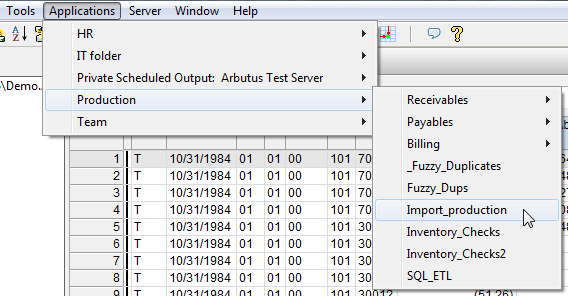
在資料表(Tables)間可以在相似的欄位上,用滑鼠右鍵點按[複製]與[貼上],任何型態的欄位包含演算欄位(Computed Fields)都可以複製與貼上,並且可以一次進行多個欄位的複製。

The Match function will take an array of values, rather than needing to specify them individually. If 'list' is an array of 100 items to be matched against, 'value', match(value, list) will perform this comparison.
Average() 平均數函數能返回任意數值或陣列值的平均數。
Total()總計數函數能返回任意數值或陣列值的總計數。
Maximum() 最大值函數能返回任意數值或陣列值的最大值,反之Minimum() 最小值函數則返回最小值。
儲存欄位(Save Field)允許儲存資料表中一整個欄位的資料到變數陣列,儲存下來的物件能被單獨使用。使用者能使用這個方法製作對話視窗中的下拉式選單。而此功能執行效率也非常迅速,能替代相對較緩慢的RECOFFSET函數。
NTOD() 日期函數能將分別輸入的時、分、秒數值返回成日期格式。這個函數在日期是計算出來的時候特別有用。
當使用者在指令視窗中選擇所須的欄位後,能使用「上移」及「下移」按鈕來重新排列欄位順序 。對於欄位數多的資料表,此功能可以加快選取效率,避免重新選取所有欄位的情形。
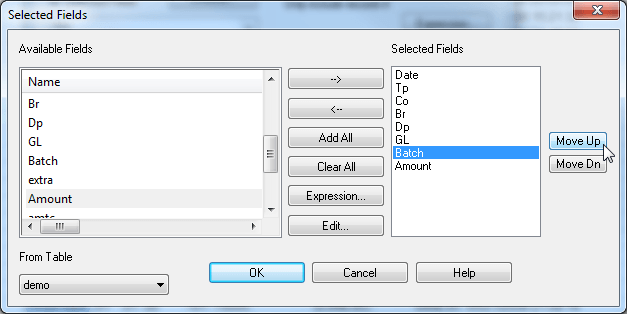

Performance Comparison: Arbutus vs. The Competition
XML: 74 times faster
Delimited/CSV: Instantaneous
XLS/XLSX: 2 times fasterExporting
XML: 4 times faster
XLS/XLSX: 3 times fasterFuzzy matching: 11 to 500 times fasterUse of time fields: 2 to 3 times faster
1) In Arbutus, Import CSV takes zero time, regardless of file size, as delimited data is read directly.
2) Our Duplicates command is compared to their FUZZYDUP.
3) As their FUZZYDUP command does not support 'same' fields, we have concatenated the three keys.About the Tests:
- Test computer specs: Dell I7-920, 2.67GHz, Windows 64 bit, 9GB RAM, 1TB disk
- Most reads use a 125,000,000 record, 80 bytes long transaction file (10GB data size)
- Fuzzy duplicates tests use a 50,000 record address file
- Exports are 5,000,000 records, except Excel, which is 650,000
- Imports are all 650,000 records
- We chose 125 million records because most people interested in performance have big data. For comparison, Arbutus also ran the "big data" tests (Join through Summarize) on a 5 million record file as well. Analyzer took 50 seconds in total, while the competitor's version 10 took 89 seconds (the graph lines were too small to show individually).




{kind=link}