[請點按左列各項理由顯示內容]
Arbutus 不仰賴微軟的XML解析器,而是改用自己發展的XML轉換器,它的處理速度更快,經常在數秒之間完成結果,除此之外,XML的介面允許我們單選包含與不包含任何項目或群組。
Table definitions may include fields that are conditional in nature, meaning they only take on a value when the specified condition is true. Where a table definition requires conditional fields, Arbutus offers an easy means to set the condition. You may select any set of fields, and in one operation, set a condition on all of them.
Where the table layout is coming from COBOL, additional sort options allow you to place related field definitions together, to simplify the selection of fields.
Arbutus logs all processing activity in a log file as supporting documentation. When a project involves several separate documentation threads, you can switch between logs with a simple click in the Overview.
The maximum record length supported by Arbutus is 2GB. While you are unlikely to ever encounter a record length this long, the capability often allows an entire file to be read as a single record, for specialized processing.
In addition, it is not uncommon for normal text (CRLF) files to occasionally have unexpectedly long lines that will likely exceed the table definition. This may be due to data corruption or an unexpected or unusual situation. When this occurs, Arbutus automatically compensates, reading the entire line despite the fact that it violates the table layout.
Arbutus supports exports to all versions of Excel spreadsheets, including XLS and XLSX. Of course, when exporting to either of these formats, you can specify the sheet name to be created, and even create multiple sheets, if necessary.
Certain processing situations require that you inspect the entire record as a single unit. For example, you may be looking for something or extracting something. When looking for something, the At() function allows you to specify RECORD as the last parameter. When extracting something, the Substring()function allows the first parameter to be RECORD.
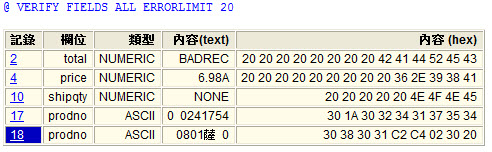
The results of a Verify command are typically presented in a tabular format. This table includes the record number, field name, expected field type, as well as the contents of the field both in text and hex. In addition to displaying the error, this table includes drill-down links, so that you can immediately move to the selected record and evaluate the error in the context of other fields and records around the error.
Certain field types store values as multiples of a larger value. For example, "Sales" might be the sales figure in thousands, so 125 stored in the field actually means 125,000.
One solution to this issue is to create a computed field to multiply by 1,000, but Arbutus offers another approach. In the same way that you can specify that a number includes decimals (effectively moving the decimal point to the left), you can specify negative decimals (effectively moving the decimal point to the right).
In this example, specifying decimals of -3 will ensure that the value is correct.
The procedure editor automatically indents commands in a Group.
The Ftype() function is used to either validate user input (ensuring that the supplied information is valid) or to ensure that the prerequisites for a particular test or calculation are present. Usually this validation involves testing that an object has a specific type, or perhaps a limited range of values.
To address this situation, the Ftype() function includes an optional parameter that allows you to specify which types are valid. If the object does not exist, or is not one of the valid types, then the function returns "U" for "Unknown".

Performance Comparison: Arbutus vs. The Competition
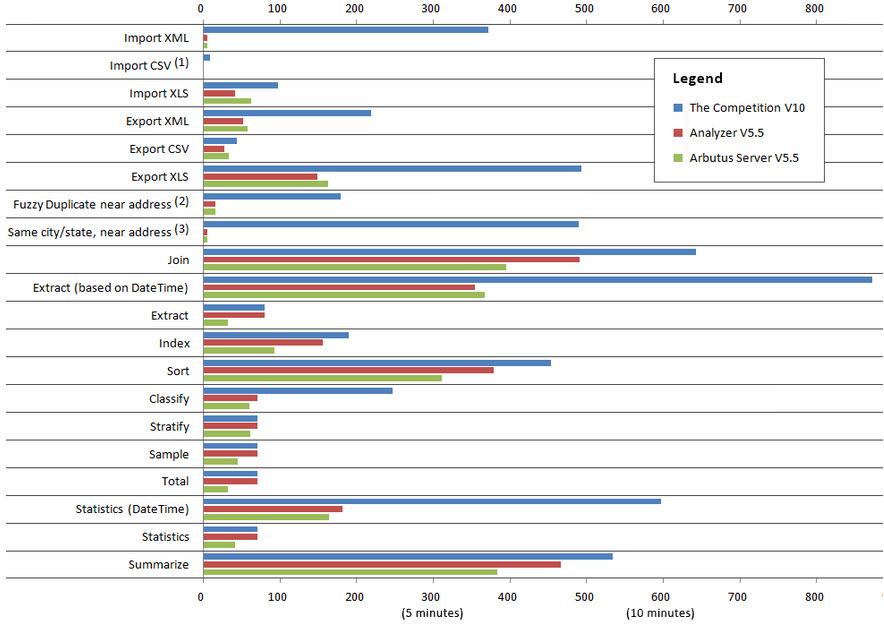
Importing
XML: 74 times faster
Delimited/CSV: Instantaneous
XLS/XLSX: 2 times fasterExporting
XML: 4 times faster
XLS/XLSX: 3 times fasterFuzzy matching: 11 to 500 times fasterUse of time fields: 2 to 3 times faster
Notes:
1) In Arbutus, Import CSV takes zero time, regardless of file size, as delimited data is read directly.
2) Our Duplicates command is compared to their FUZZYDUP.
3) As their FUZZYDUP command does not support 'same' fields, we have concatenated the three keys.About the Tests:
- Test computer specs: Dell I7-920, 2.67GHz, Windows 64 bit, 9GB RAM, 1TB disk
- Most reads use a 125,000,000 record, 80 bytes long transaction file (10GB data size)
- Fuzzy duplicates tests use a 50,000 record address file
- Exports are 5,000,000 records, except Excel, which is 650,000
- Imports are all 650,000 records
- We chose 125 million records because most people interested in performance have big data. For comparison, Arbutus also ran the "big data" tests (Join through Summarize) on a 5 million record file as well. Analyzer took 50 seconds in total, while the competitor's version 10 took 89 seconds (the graph lines were too small to show individually).




{kind=link}