[請點按左列各項理由顯示內容]
61.匯入資料表時自訂編輯SQL查詢指令62.欄位陣列(Field Arrays)63.跨平台的程序(Procedure)支援能力64.排序/索引的效能增強65.日期及時間的處理指令66.嚴重錯誤(Fatal Error)程序的處理能力67. NOFORMAT輸出函數68. EOMONTH()函數69. 可自行選擇程序編輯器中的色彩70. 完整支援iSeries (AS/400)伺服器
透過ODBC匯入資料表時,使用者能夠在匯入資料表前使用SQL查詢指令,使用者可編輯進階的SQL語法在資料表匯入的同時,篩選或合併所需的資料,而不受ODBC介面的限制。

通常資料表檔案包含欄位組合是相同的,除了所引用的資料欄位。一個常見的例子為年度預算,每月的金額應為相同金額。當您的資料有此特點時,Arbutus允許您定義一個陣列組合欄位,如此一來,您就不需要單獨定義每個欄位。您可以在任何欄位中建立個別的陣列組合,此功能支持:
- 陣列欄位屬於實體相鄰,如Jan_amt, Feb_amt, Mar_amt,...
- 重複性的結構陣列,像code1, date1, amt1, code2, date2, amt2, ...
Arbutus的程序(Procedure)支援在任何Arbutus所支援的平台上運行,使用者能在本機電腦上建立所需執行的程序後,即可在Aubutus所支援的伺服器平台(Windows, MVS/zSeries, AS400/iSeries)上運行,這對於使用者開發自動化程序是一大利器。
Arbutus能充分利用個人電腦與伺服器的效能,提高執行排序/索引指令的執行效率。Arbutus還提供先進的動態分配記憶體的處理能力,允許在特殊情形下作進一步的優化。
Arbutus可以轉換任何組合的日期時間欄位,例如:
- Year() 函數能將年份回傳為數值型態,如:2012
- Month()函數能將月份回傳為數值型態,如: 12
- Day()函數能將日/天回傳為數值型態,如: 31
- Hour()函數能將小時回傳為數值型態,如: 23
- Minute()函數能將分鐘回傳為數值型態,如: 59
- Second()函數能將秒回傳為數值型態,如: 42
意外(或故障)可能發生,有時候程序不會按預期執行結果。Arbutus可以在發生錯誤時,通過SET FATAL指令進行處理。該指令允許變數回應,根據程序的需要。例如,發生錯誤時,使用者可以:
- 當Arbutus關閉時,會返回一個特定值給被呼叫的程式。這對於Arbutus是用來被其他程式當作“處理引擎”時,是很有效的功能。
- 當錯誤的程序發生時,返回正在執行的程序,並繼續呼叫程序。這在(大)量的獨立測試中的情況下是很有效的功能,這意味著一個失敗的測試,並不會影響其他測試的運行。
- 自動運行特定的“clean up” 程序。有可能恢復一些在程序上所發生的錯誤,或者應該進行額外的步驟去解決執行的錯誤。(如向管理員發送電子郵件)。
- 此功能特別能用於ETL處理,用作刷新資料表資料使用。使用此函數能不影響資料表定義下刷新資料,特別是資料表定義中含有演算欄位或其他的篩選規則
- 使用NOFORMAT函數,能在建立資料表時不建立新的資料表定義,此功能可以讓ETL處理更新資料時不會破壞原有的資料表定義與環境。
EOMONTH() 函數可返回指定日期該月的結束日期與時間。它通常可用於特殊的運算。
- 例如2012年8月14日,使用EOMONTH函數可得到以下結果:
»EOMONTH(‘20120814‘) = ‘20120831 23:59:59‘
所有在Arbutus程序編輯器中顯示的色彩都是可自行定義的,此功能可方便使用者依據需求自定義,也能很好地適應某些色彩顯示受限的顯示設備。
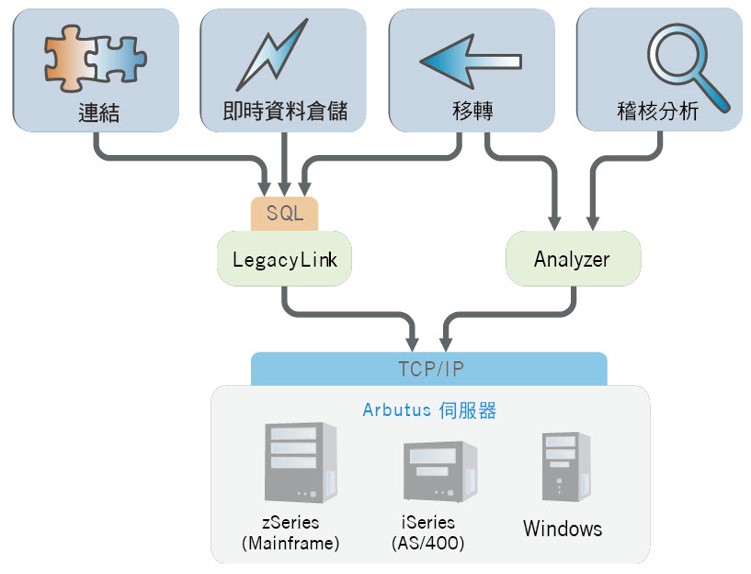
- Arbutus完整支援iSeries伺服器,可讓使用者完整的存取iSeries伺服器。使用者不僅能存取DB2,也能存取Flat File, IFS File以及SPOOL File
- Arbutus iSeries伺服器提供良好的安全性,以唯讀的方式存取任何類型的資料,使用標準的登入協定,隨時地維護資料安全。

Performance Comparison: Arbutus vs. The Competition
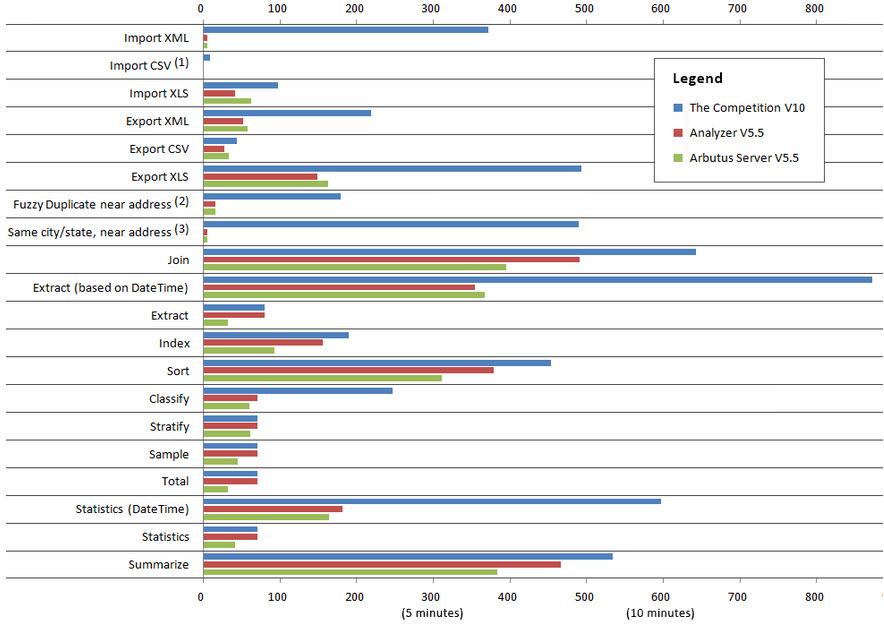
Importing
XML: 74 times faster
Delimited/CSV: Instantaneous
XLS/XLSX: 2 times fasterExporting
XML: 4 times faster
XLS/XLSX: 3 times fasterFuzzy matching: 11 to 500 times fasterUse of time fields: 2 to 3 times faster
XML: 74 times faster
Delimited/CSV: Instantaneous
XLS/XLSX: 2 times fasterExporting
XML: 4 times faster
XLS/XLSX: 3 times fasterFuzzy matching: 11 to 500 times fasterUse of time fields: 2 to 3 times faster
Notes:
1) In Arbutus, Import CSV takes zero time, regardless of file size, as delimited data is read directly.
2) Our Duplicates command is compared to their FUZZYDUP.
3) As their FUZZYDUP command does not support 'same' fields, we have concatenated the three keys.About the Tests:
1) In Arbutus, Import CSV takes zero time, regardless of file size, as delimited data is read directly.
2) Our Duplicates command is compared to their FUZZYDUP.
3) As their FUZZYDUP command does not support 'same' fields, we have concatenated the three keys.About the Tests:
- Test computer specs: Dell I7-920, 2.67GHz, Windows 64 bit, 9GB RAM, 1TB disk
- Most reads use a 125,000,000 record, 80 bytes long transaction file (10GB data size)
- Fuzzy duplicates tests use a 50,000 record address file
- Exports are 5,000,000 records, except Excel, which is 650,000
- Imports are all 650,000 records
- We chose 125 million records because most people interested in performance have big data. For comparison, Arbutus also ran the "big data" tests (Join through Summarize) on a 5 million record file as well. Analyzer took 50 seconds in total, while the competitor's version 10 took 89 seconds (the graph lines were too small to show individually).




{kind=link}