[請點按左列各項理由顯示內容]
當我們透過ODBC讀取資料庫資料時,Arbutus的資料定義精靈可以讓使用者一次匯入及定義多個資料表,而不是每次只能定義一個資料表。這將大大地簡化使用者在資料處理的效能與效率。
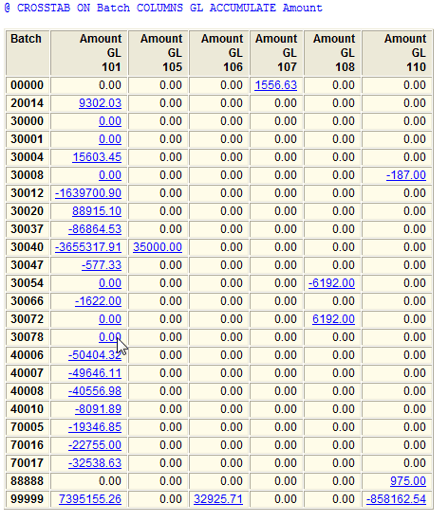
Arbutus支援交叉分析資料,使用交叉分析指令(CrossTabulate)所產出分析結果能個別下探(Drill-down)該數據資料源明細。
此外,如果產出交叉彙總數是零(Net to zero),也會明顯地顯示出來超連結,允許下探該數據資料的詳細內容,但若是沒有實際彙總資料,則不會顯示出超連結,雖然它們都顯示零,但代表的涵義是有區別的。
Arbutus的Cmon()指令,可以讓使用者指定日期的月份,或是輸入字串方式傳回該日期或字串所在的月份。此功能與Cdow()功能相似,Cdow()指令能讓使用者指定日期,並傳回星期幾。 Cmon()指令的使用方法如下:
- CMON(Christmas, 3)= “Dec”
- CMON(‘20120814‘,3) = "Aug"
- CMON(‘20120814‘,6) = "August"
進階的使用者常常需要調整資料表各欄位的格式,Arbutus能使用DISPLAY TO指令匯出整個資料表格式,包括記錄長度、文件名稱以及所有的欄位定義以及欄位說明。匯出的資料表能進行進一步的查詢或使用程序(Procedure)進行資料分析。
Arbutus支援多樣化的資料型態,因為支援多種不同的資料來源,Arbutus特別以不同樣式標示不同的資料型態,讓使用者方便辨識。以下簡述幾種特別需要注意的部份:
- 可重新整理的資料來源(例如:Excel),會在資料表圖示中顯示藍色標記,您可從藍色標記來得知該資料為可重新整理的資料來源。
- 直接讀取的資料來源(例如:ODBC),會在資料表圖示中顯示紫色標記,您可從紫色標記來得知該資料為每次開啟即重新連結來源資料。

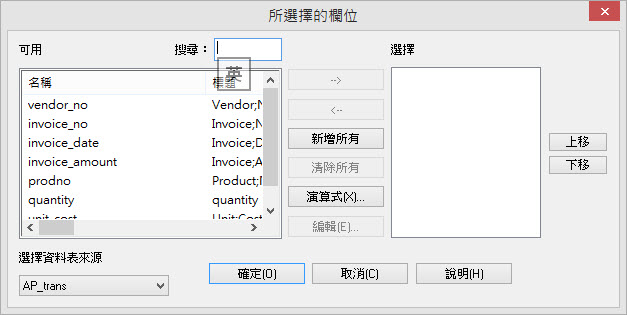
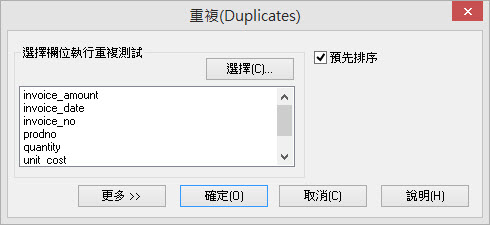
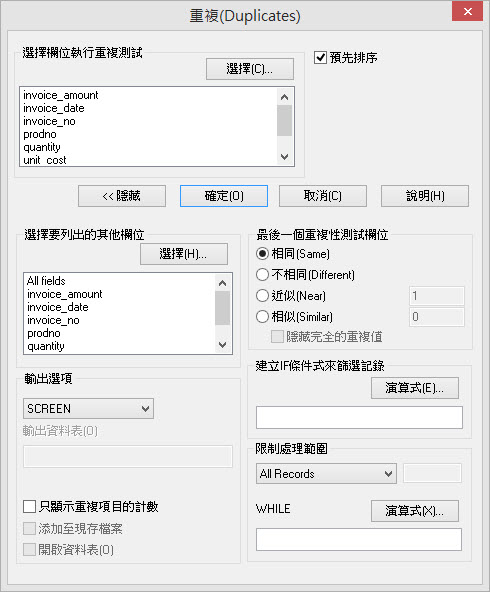
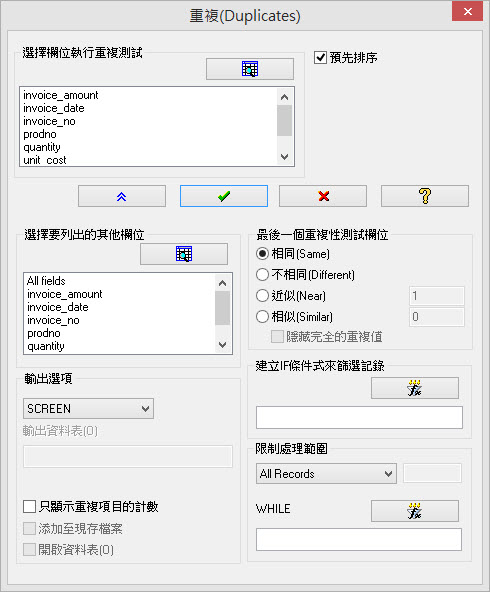
Arbutus致力於確保指令對話框的高度可用性,對於不同的資料分析指令對話視窗均使用統一的介面,簡化使用介面讓初階使用者也能快速上手。對於進階使用者,Arbutus也提供許多進階選項供進階使用者使用。
Arbutus的指令對話框的使用介面提供了文字按鈕以及圖示按鈕的方式,使用者能依據個人喜好,選擇顯示方式。
Replace()函數是一個非常強大的資料調整處理功能,它能被用於修飾字元資料以符合使用者預計需求,可依據使用者需求尋找資料中的特定子字串(Sub-String)並替換。
Replace()函數能允許使用者指定任意成對數量的字串替換, Replace()函數函數的語法如下:
- –Replace(name, “;”,“-”, “~”,“ ”, “Hours”,“Hrs”, “*”,“”) 這串指令能將字串中,每個 「;」用「-」替換,每個「~」用一個空白字串替換 ,每個「 Hours」用「 Hrs」替換以及每個「*」用空白字串替換。
- –舉例來說:Replace("Boston (+3 Hours)~Chicago(+2 Hours); Arr. 7:15** AM", ";","-", "~"," ", "Hours","Hrs"", "*","") ="Boston (+3 Hrs) Chicago(+2 Hrs)- Arr. 7:15 AM"
除了Replace()函數提供的替換字元功能,Arbutus 也能使用Include(), Exclude(), and Remove() 擷取基於特定範圍的字元。
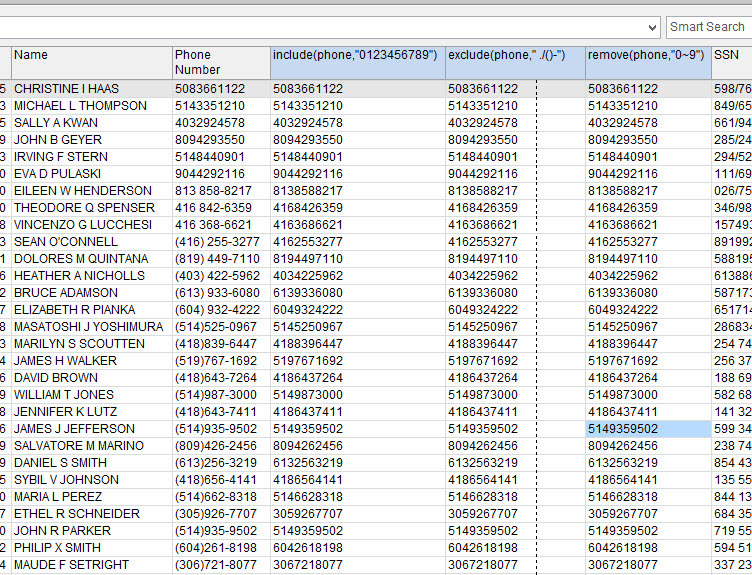
例如,Include(fieldname, “A~Z”) 能只篩選出欄位中包括大寫A~Z的資料。
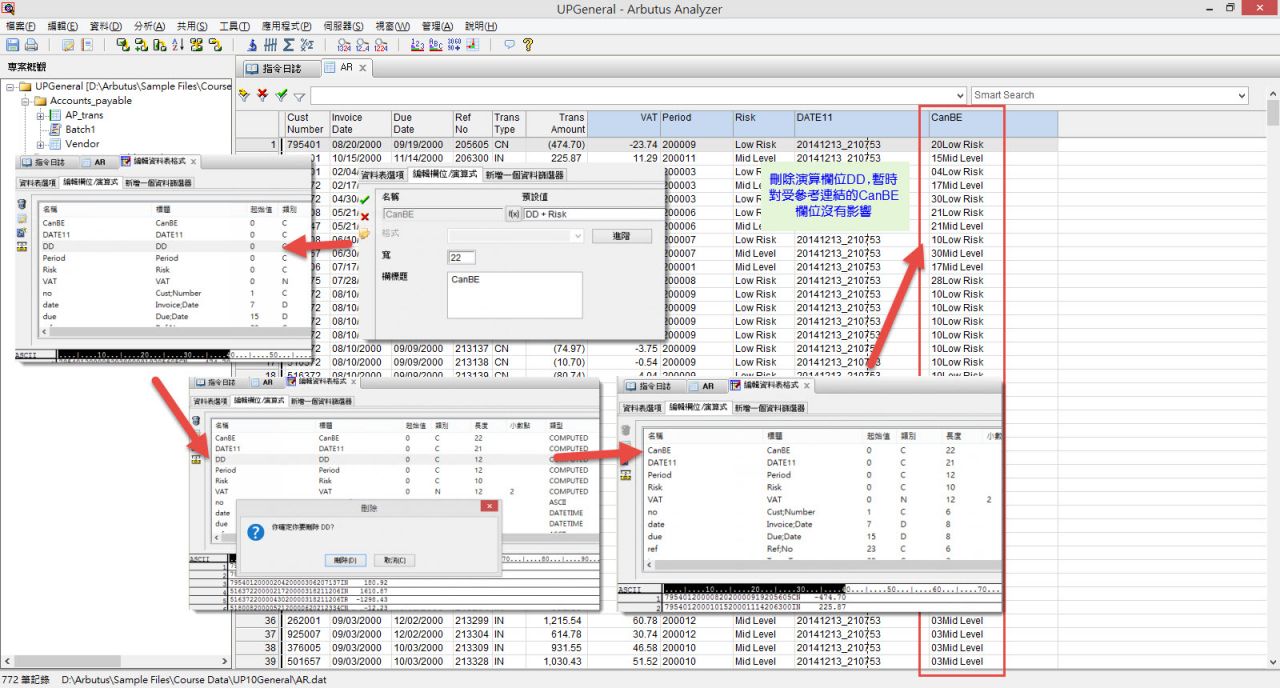
資料表定義經常需要新增虛擬或演算欄位來進行特別營運作業或驗算,必需要的是這些欄位常被連結參考至其他欄位定義裡,在Arbutus系統中,有參考到其他地方的欄位可以從資料表定義中刪除或變更,即使它暫時中斷資料格式定義的完整性,你只要在需求以前,更換欄位,那就沒有問題了。
在IBM大型主機(Mainframe)中,與IMS, VSAM, DB2, 以及關聯式資料相關的關鍵欄位資訊,Arbutus均能自動識別。所辨別出的資料能自動地建立索引(尋找)以及關聯,使用者不需要手動將其個別建立索引。這確保了動態的大型主機(Mainframe)資料總是保持在最新狀態。

Performance Comparison: Arbutus vs. The Competition
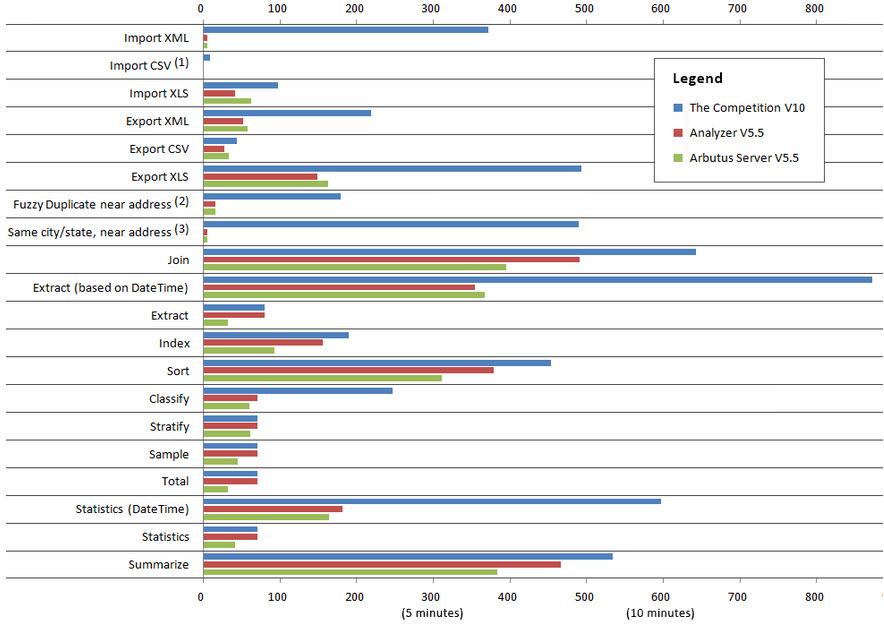
XML: 74 times faster
Delimited/CSV: Instantaneous
XLS/XLSX: 2 times fasterExporting
XML: 4 times faster
XLS/XLSX: 3 times fasterFuzzy matching: 11 to 500 times fasterUse of time fields: 2 to 3 times faster
1) In Arbutus, Import CSV takes zero time, regardless of file size, as delimited data is read directly.
2) Our Duplicates command is compared to their FUZZYDUP.
3) As their FUZZYDUP command does not support 'same' fields, we have concatenated the three keys.About the Tests:
- Test computer specs: Dell I7-920, 2.67GHz, Windows 64 bit, 9GB RAM, 1TB disk
- Most reads use a 125,000,000 record, 80 bytes long transaction file (10GB data size)
- Fuzzy duplicates tests use a 50,000 record address file
- Exports are 5,000,000 records, except Excel, which is 650,000
- Imports are all 650,000 records
- We chose 125 million records because most people interested in performance have big data. For comparison, Arbutus also ran the "big data" tests (Join through Summarize) on a 5 million record file as well. Analyzer took 50 seconds in total, while the competitor's version 10 took 89 seconds (the graph lines were too small to show individually).



