[請點按左列各項理由顯示內容]
Arbutus允許使用者儲存許多不同的變數在變數陣列中,陣列可儲存的空間是依據使用者電腦中的記憶體(RAM)而定,代表有可能使用者儲存數以百萬計的陣列。使用者能自行利用指定值的方式創建陣列值,或者是使用SAVE FIELD的指令創建陣列值。使用SAVE FIELD的指令能將整個資料表欄位轉換為變數陣列。陣列能被使用在:
- 儲存表格資訊
- 提供指令的輸入值
- 增加效能
- 支持透過對話框自訂使用者介面
當使用者讀取試算表或存取資料表時,可以選擇建立平面化資料檔,或者是使用直接連結的方式讀取資料來源檔。平面化資料來源檔能確保該資料不會被隨意修改,而直接讀取資料來源,能確保每次所讀取的資料都是最新更新過的資料。
當使用者在定義資料表格式時,Arbutus會自動地將資料定義區域以最大化視窗寬度的方式填滿螢幕,方便使用者檢視資料態樣。
當使用者利用重複(Duplicate)指令分析資料時,Arbutus於指令日誌中顯示出來的分析結果,僅會依照關鍵(Key)欄位的唯一值顯示出分析結果,而不用檢視細項。此功能讓使用者能快速找尋是否有重複的值。Arbutus亦提供了下探明細(Drill-Down)的功能,讓使用者透過超連結直接檢視完整重複明細。

當使用者存取可更新資料來源資料時(例如試算表以及XML檔),Arbutus能直接重新連結不同的資料來源檔。就算是該資料已經被轉換為平面化資料檔亦可重新連結資料來源。
當使用者編輯資料表格式時,能夠檢視整個資料檔案的資料,即使該資料有幾百萬筆。您可使用滑鼠滾動以及鍵盤換頁的方式瀏覽資料,也可以直接定位到資料表中的某一行資料。

當使用者刪除資料表(Table)時,與該資料表(Table)相連結(Link)的實體檔案也會聰明地被刪除。如果Arbutus建立資料表資料,那麼Arbutus預設會自動刪除與其關聯的實體資料檔案。當然,使用者還是可以自行控制該實體檔案是否要連同資料表格式一起刪除。如果該資料表是原始的來源資料檔(在資料定義精靈中定義),那麼實體資料檔案就不會被刪除。
使用者可以指定一個自動的暫時性檔案前綴值,使用者指定暫時性檔案前綴值後,只要是套用該前綴值設定的資料表,Arbutus會於程式關閉時刪除與該資料表相關的所有物件。暫時性檔案前綴值能套用在任何物件型態(包含資料表、索引以及程序)中。
當使用者萃取資料或匯出資料時,可指定將資料表預先排序,這大大簡化了建立資料檔案的步驟。
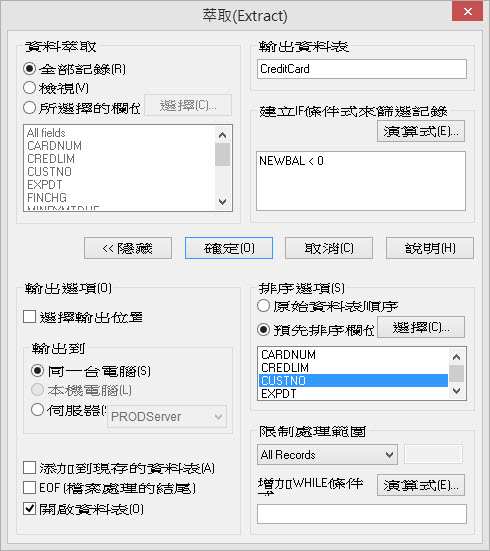
Arbutus專案中任何的物件都能被隱藏起來,來提昇使用者介面體驗。此功能可以用在預防執行過程中的檔案出現在專案概觀(Overview)區域中,也可利用此功能隱藏不需顯示出來的程序(Procedure)。
隱藏的物件可以以同樣的方式由任何其他人讀取,只要知道這個物件名稱就可以,這通常不是一個問題,因為大部分隱藏的物件僅只於由程序(Procedure)來引用,藉著使用Arbutus,還是可以顯示隱藏的物件,你是否應該忘記名稱或是需要連結它們進行編輯。

Performance Comparison: Arbutus vs. The Competition
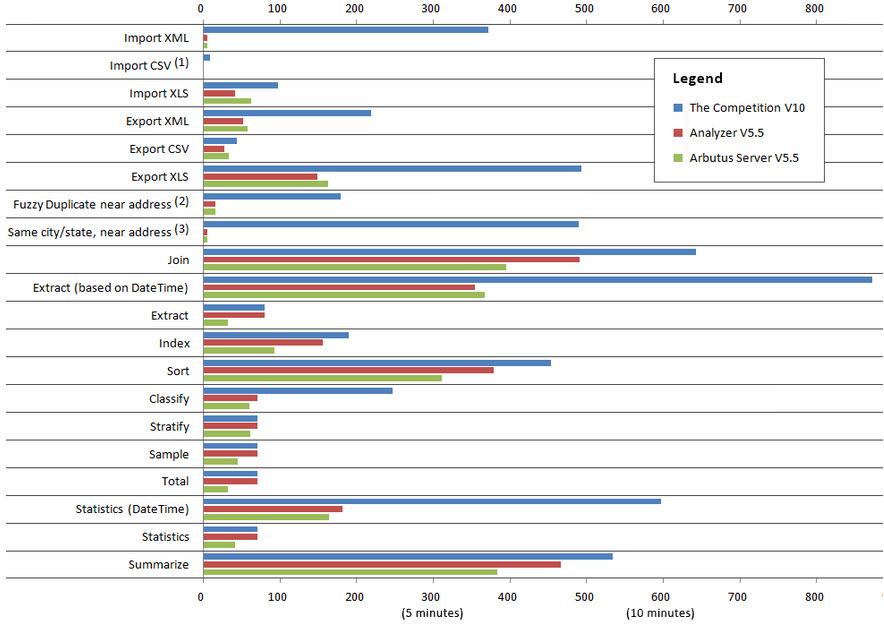
XML: 74 times faster
Delimited/CSV: Instantaneous
XLS/XLSX: 2 times fasterExporting
XML: 4 times faster
XLS/XLSX: 3 times fasterFuzzy matching: 11 to 500 times fasterUse of time fields: 2 to 3 times faster
1) In Arbutus, Import CSV takes zero time, regardless of file size, as delimited data is read directly.
2) Our Duplicates command is compared to their FUZZYDUP.
3) As their FUZZYDUP command does not support 'same' fields, we have concatenated the three keys.About the Tests:
- Test computer specs: Dell I7-920, 2.67GHz, Windows 64 bit, 9GB RAM, 1TB disk
- Most reads use a 125,000,000 record, 80 bytes long transaction file (10GB data size)
- Fuzzy duplicates tests use a 50,000 record address file
- Exports are 5,000,000 records, except Excel, which is 650,000
- Imports are all 650,000 records
- We chose 125 million records because most people interested in performance have big data. For comparison, Arbutus also ran the "big data" tests (Join through Summarize) on a 5 million record file as well. Analyzer took 50 seconds in total, while the competitor's version 10 took 89 seconds (the graph lines were too small to show individually).



