[請點按左列各項理由顯示內容]
Arbutus提供持續性監控的能力,不需要另外學習新工具、轉換資料及程序(Procedure)到其他產品,或者是購買附加軟體。你的所有測試及結果都能在企業共用資料夾中統一存放管理,並能透過Arbutus Analyzer簡單地進行部屬、排程及管理

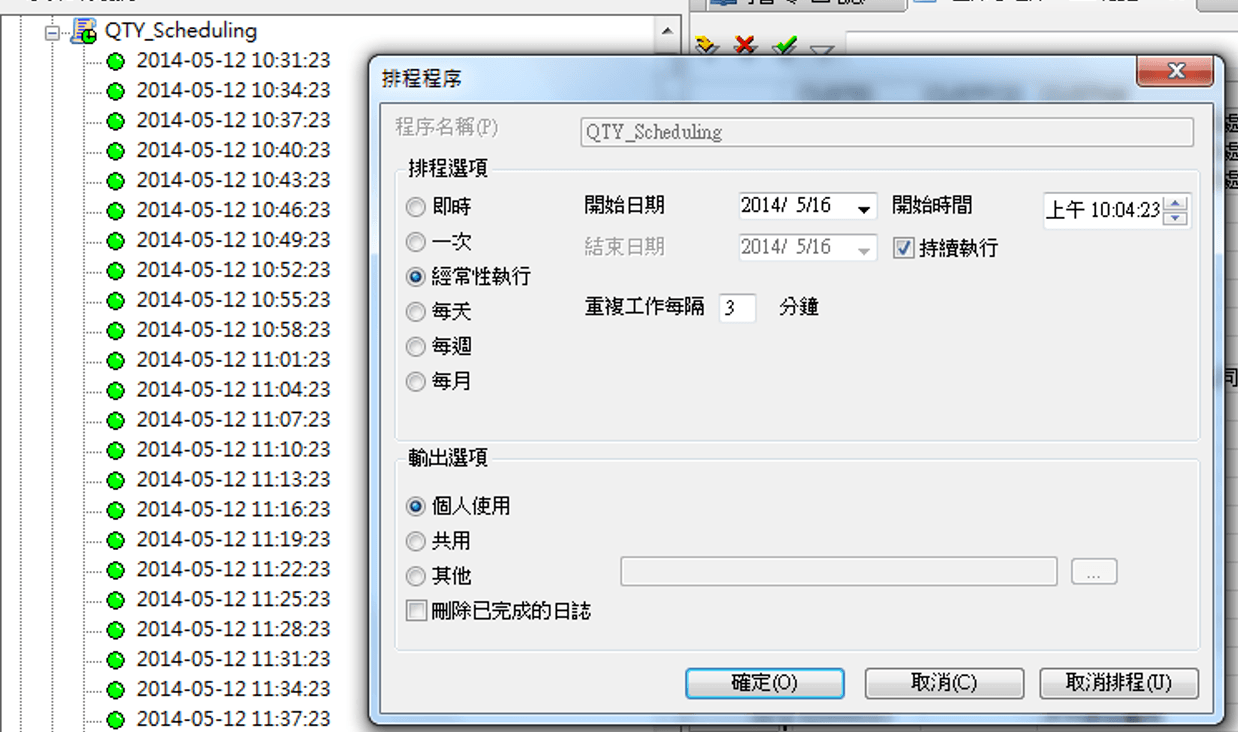
此外,您可以選擇「排程」選項設定每一項元件的系統自動執行時間及週期(每日、周、月及特定時間)
- 排程結果日誌會顯示於概觀視窗中,且會以顏色圓球註明排程執行的狀態。紅色圓球代表執行失敗,綠色圓球代表執行成功,您可以透過撰寫程式的方式編輯若是遇到錯誤條件時即顯示黃色圓球。
- 除了顯示執行日期以及結果,也會於概觀視窗中顯示異常發生的次數。
Arbutus 允許任何物件被共用,從資料表、程序(Procedure)、檢視(Views)到任何專案中的物件都能利用內建的『共用資料夾』功能共用。『共用資料夾』能被建置在企業辦公室內、可跨部門甚至跨區域使用,且沒有數量限制地允許任何專案或使用者共享相同的物件定義檔。這個功能大幅度地減低部屬跨部門使用者環境的管理成本。任何資料表、程序(Procedure)或其他物件都能被共享:
- 共用通用資料表,確保所有使用者共享相同的定義檔,最小化編輯以及新增資料表的難度。
- 共用通用程序(Procedure),確保所有使用者能輕易地存取程序,透過將程序存放於同一儲存位置共用,能最小化與新增/修改刪除相關的部屬問題。
- 被共用的程序會自動地出現在應用程式選單上,方便直接點選執行。
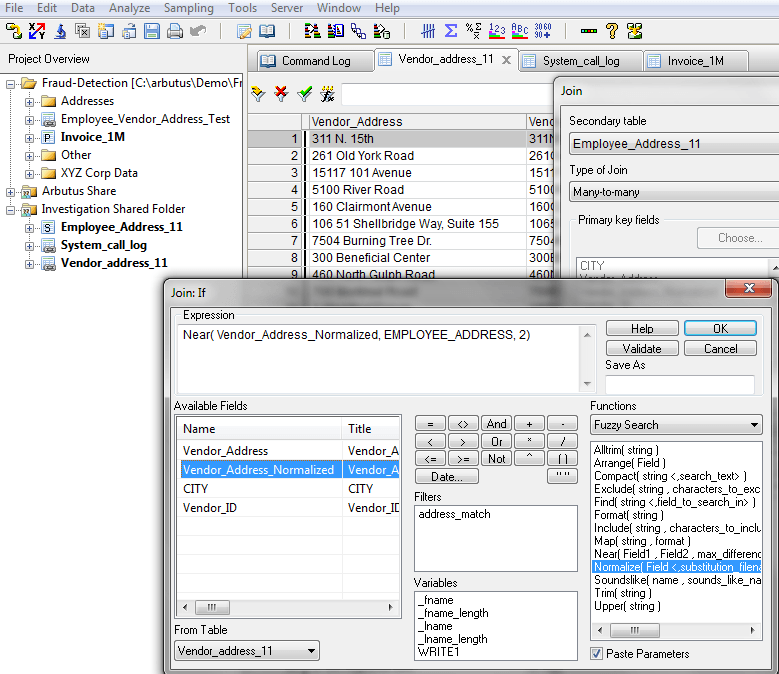
比較姓名及地址時,最重要的就是除去不重要的差別,這是將資料“正規化”的過程。例如,地址中的街道,可能會使用“Avenue”或”Ave”等不同寫法。我們可以利用Arbutus提供的簡單功能,正規化大多數的名稱和地址。
獨特的Arbutus正規化功能包括:
- Normalize功能自動地消除最常見的差異當您比較名字或地址時,舉例來說地址”#200-1234 Main Street”以及”200 1234 MAIN ST.”利用此功能則可將這兩個格式不同但實際相同的地址辨認為相符,且不需要任何的模糊比對功能。正規化能自動地辨識地址大小寫、標點符號等差異。而且,內建的單詞替換表可以消除不必要的字詞(像是”Suite” 或是”Mr.”,以及常見的縮寫和拼寫錯誤(例如,Avenue, Ave., Av,. …),將其標準化。
- SortNormalize功能將Normalize功能更進一步提昇,它能排序已被正規化的字詞。透過此功能,像是”#200 – 1234 Main Street West” 以及 “1234 W MAIN ST, Suite 200”這兩種地址形式就可以被完全匹配。
- Compact功能移除欄位中間多餘的空白,增加使用者鍵入資料的可比較性。
- Arrange功能消除因字元換位所造成的差異,像是因為排序欄位中的字元造成”604 437 7872” 變成“877644320”的差異。
Arbutus是目前為止最快速的審計工具,比起其他的審計工具提供了更強大的模糊比對的功能,優異的執行效能讓其他競爭者望塵莫及。Arbutus能利用模糊比對的功能在分秒之間就能比對上百外筆的資料,而相比其他對手,可能需要花費幾小時甚至是一整天的時間來執行相同的比對測試。
Arbutus模糊比對功能包括:
- Duplicate Near, Duplicate Similar 以及 Duplicate Same-Same-Near 能在極短的時間內執行重複測試,例如,測試有無同一供應商、同一日期、同一金額以及同一張發票的情形,僅需簡單幾個步驟即可完成。以測試地址來說,例如相近的地址在同一個城市和國家,Arbutus可能在幾秒鐘內從大型資料檔案中找尋出想要的結果
- 不同(Difference):是利用 Damerau-Levenshtein 距離演算法計算字串差異, Damerau-Levenshtein 距離演算法比 Levenshtein 距離演算法更加完善,提供更進階的演算方式,能比對因字元順序更動所造成的差異(例如,123456 vs. 124356),顯著降低判斷錯誤發生。
- 近似(Near):辨識任何類型資料中”相近”的物件,利用 Damerau-Levenshtein 距離演算法判別文字型欄位,也能使用於辨認相近的日期或金額。
- 相似(Similar):是Levenshtein距離演算法的特殊變異比對技術,是設計來比對”看”起來相似的物件。針對文字型欄位,它在比對前會事先移除所有非字母數字的資料,接者找出所有“看”起來相似的字元(例如,I 和 1)。針對數值型、日期型欄位,可利用此功能來尋找數字換位或看起來非常相似的數值。
- Listfind功能:利用此功能,可簡易地找尋出任何想尋找的數值,將欲搜尋的數值儲存在簡單且易維護的列表中,並能無限制地搜尋想要搜尋的條件。此功能可用於FCPA合規審計中的採購卡(PCard)查核,運用簡單的指令Listfind(“FCPA List.txt”)即可找尋到所有指定搜尋的字詞。
Arbutus可以直接嵌入任何SQL指令至您的分析專案中,您可以利用這個技術來分析、結合或比較來自相同或不同的SQL環境的資料。利用SQL語言的普遍性以及有力性來檢索您的資料,結合Arbutus所提供的強大分析能力,能讓您的分析產出更加有效。
SQL指令能在Arbutus 程序(Procedure)中的任何地方使用,且支援所有使用SQL指令的資料庫系統。
Arbutus提供無與倫比的分析性能表現,在任何領域的執行效能均同於或高於競爭對手。根據您所執行的工作,Arbutus能在以下幾個方面提供極佳的效能(與競爭對手相比):
- 匯入XML快70倍
- Delimited/CSV檔案瞬間匯入,因為Arbutus在匯入資料時不需轉換格式
- 執行模糊比對大型檔案僅需幾秒鐘的時間
- 匯入及匯出試算表檔案快200~300%
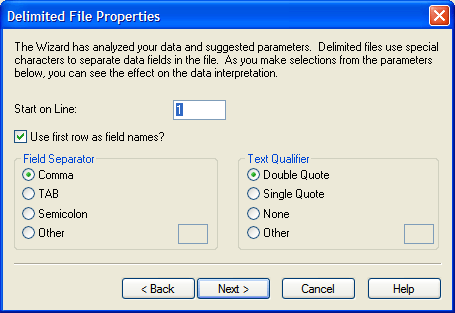
不論任何大小分界檔(Delimited File),Arbutus都能直接讀取而不需做任何轉換格式的動作
- 不需等待轉換格式的時間,資料會即時讀入
- 不需將原始檔製作副本
- 支援所有的分界檔格式(TAB, Comma, Pipe, etc.)
- 資料表定義能容易地被調整來支援新資料
- 資料表定義能對新資料使用驗證(Verify)指令進行測試
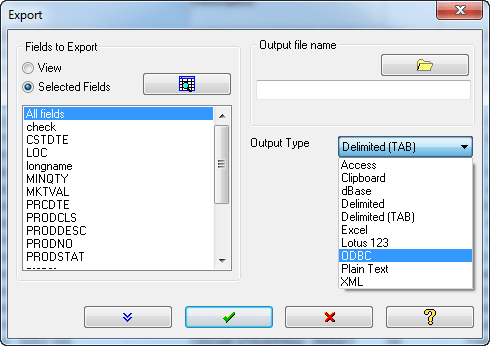
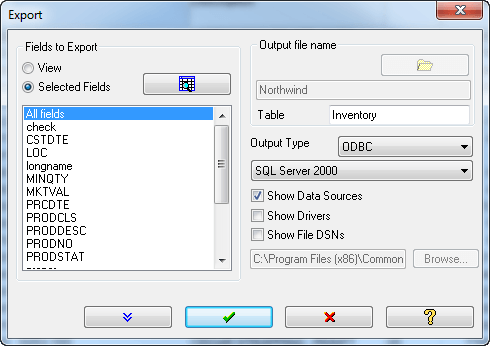
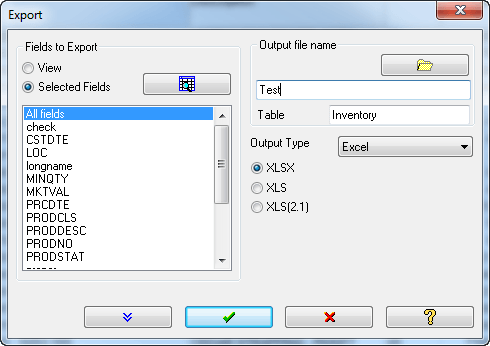
Arbutus的匯出(Export)指令提供了各式各樣的應用程式整合能力,提供了完美的整合能力。除了所有標準的匯出資料的類型外,還提供了以下功能:
- 匯出至ODBC:可匯出資料表資料至 SQL, Oracle, 及任何 ODBC 連結 Database,供其他應用系統連結查詢使用。
- 匯出多個資料表至Excel 試算表:可匯出多個資料表至單一 Excel檔,不會覆蓋原先存在於 Excel的工作表,可利用此功能製作 Summary/Dashboard 報表。
Arbutus的資料表檢視包括強大的新功能,讓您能善加利用手中的資料,功能如下:
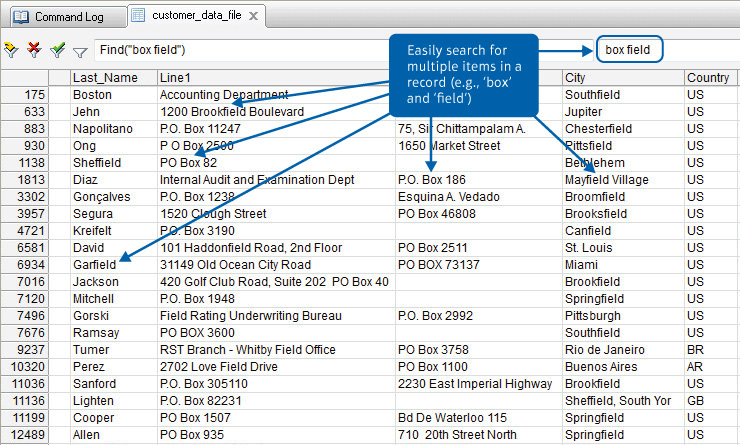
- 智慧搜尋(Smart Search):採用與 Google 概念相同的搜尋模式,方便讓您在各資料主檔中,快速找出您想要的資料。 智慧搜尋能支援各種型態的資料,您可以搜尋文字型、數值型以及日期型欄位資料。
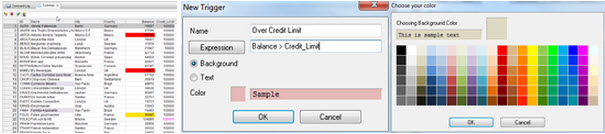
- 觸發器(Trigger):觸發器可讓您自訂資料篩選條件,使用色彩標示加強資料表內容的檢視能力。可使用觸發器的功能實現,當資料內容需要被注意時,自動標示出顏色提示。
- 快速篩選:新增近似(Near)的篩選條件,能瞬間辨識所以與所選物件近似的記錄。此功能使用 Levenshtein 距離演算法,可運用在文字型、數值型以及日期型的資料。
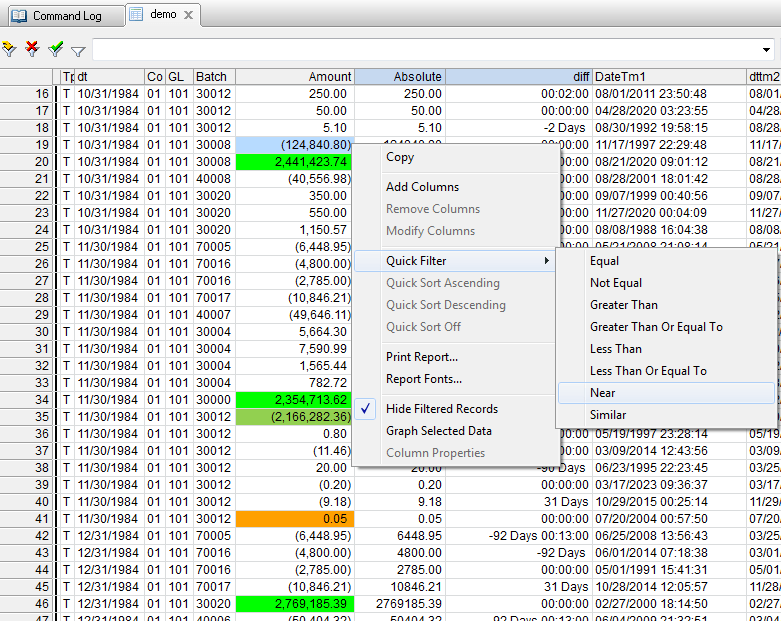
- Thin filter optimization能大幅度地提昇使用篩選器篩選資料的效能,能結果平滑呈現。提供您快速辨別有價值的資訊,而無需擔心性能所造成的影響。
- 當您於一個大型檔案中指定一個Thin Filter,移動視窗捲軸在某些產品的檢視畫面常會無法即時顯示資料全貌,但Arbutus卻能在您每次移動視窗捲軸時,即時顯示資料全貌。
Arbutus包括了各式各樣的自動化分析的功能,包括:
- 程序保護:可將程序(Procedure)進行加密保護,讓該程序僅可執行,禁止開啟及編輯,增加安全性。
- 嵌入式程序:此功能可在程序中建立子程序,子程序的數量不受限制,可存在於原程序中或是從其他程序中呼叫,方便模組化管理。
- 加強版的對話框:允許使用者製作直接選擇檔案對話框,數值型唯一和日期型唯一的欄位。此外,可設定對話框自動關閉時間,一定時間之後對話框即會關閉繼續執行後續程序(Procedure)。
- 程序設置個別獨立:所有於程序(Procedure)所作的設定會回復到前次執行完成的設定值,此功能可讓使用者將所需的設定值獨立設定於於個別程序中,不會影響其他程序。例如,如果使用者設定SET SAFETY OFF,不需在程序尾端加上SET SAFETY ON也不會影響到其他程序的設定。
- SET DEFAULT 指令:SET DEFAULT指令可使用在程序中確保所有設定都保持預設值,使用該指令可確保你的程序都是以已知的設定值運行。

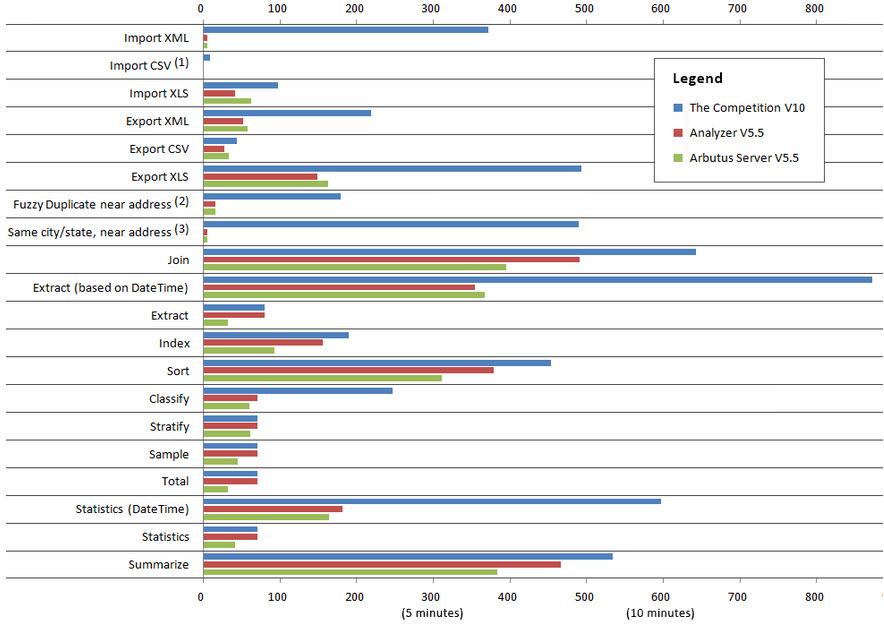
Performance Comparison: Arbutus vs. The Competition
XML: 74 times faster
Delimited/CSV: Instantaneous
XLS/XLSX: 2 times fasterExporting
XML: 4 times faster
XLS/XLSX: 3 times fasterFuzzy matching: 11 to 500 times fasterUse of time fields: 2 to 3 times faster
1) In Arbutus, Import CSV takes zero time, regardless of file size, as delimited data is read directly.
2) Our Duplicates command is compared to their FUZZYDUP.
3) As their FUZZYDUP command does not support 'same' fields, we have concatenated the three keys.About the Tests:
- Test computer specs: Dell I7-920, 2.67GHz, Windows 64 bit, 9GB RAM, 1TB disk
- Most reads use a 125,000,000 record, 80 bytes long transaction file (10GB data size)
- Fuzzy duplicates tests use a 50,000 record address file
- Exports are 5,000,000 records, except Excel, which is 650,000
- Imports are all 650,000 records
- We chose 125 million records because most people interested in performance have big data. For comparison, Arbutus also ran the "big data" tests (Join through Summarize) on a 5 million record file as well. Analyzer took 50 seconds in total, while the competitor's version 10 took 89 seconds (the graph lines were too small to show individually).



